This page briefly describes MIPSgate, which is a tiny subset of the Microprogrammed Instruction Processing Simulator (TinyMIPS), which has been implemented in GateSim logic for easy modification and extension. For a somewhat more complete specification of the MIPS architecture, see the Appendix A from Hennessy & Patterson, Computer Organization and Design (download as PDF).
TinyMIPS is more or less compatible with the SPIM
simulator, in that MIPS assembly language programs can be assembled
in SPIM, then the result saved as a log file, which TinyMIPS can read and
decode.
The following MIPS instructions should work correctly in TinyMIPS:
| Move | ALU | Jump | ||
| lui | addu | jump | ||
| lw | addiu | jr | ||
| sw | subu | jal | ||
| mfhi | and | jalr | ||
| mthi | andi | beq | ||
| mflo | xor | bne | ||
| mtlo | xori | blez | ||
| slt | bgtz | |||
| sltu | bltz | |||
| slti | bgez | |||
| sltiu |
The three signed arithmetic operations, add, addi, and sub, work exactly the same as their unsigned cousins. The only effective difference between them and MIPS is that they cannot cause an exception in case of overflow.
The pseudo-instruction li (load immediate) sometimes assembles to the machine operation ori, which is not implemented in TinyMIPS; the ori instruction executes as xori, which gives the same results in the li pseudo-instruction sequence, and wrong results otherwise. Similarly, the nop (no operation) pseudo-instruction is actually a special case of the MIPS sll instruction, shifting register 0 left 0 places; in TinyMIPS all sll instructions are no-operations. The TinyMIPS syscall instruction is also implemented as a nop. These adaptations were necessary to accommodate the code generated by the SPIM assembler.
The sra (shift right arithmetic) instruction is the only shift
implemented in TinyMIPS, and it only shifts one bit; any attempt to shift
more than one place will be ignored.
Perhaps when I figure out how to make a C program with
a decent face on it, this will be easier to use.
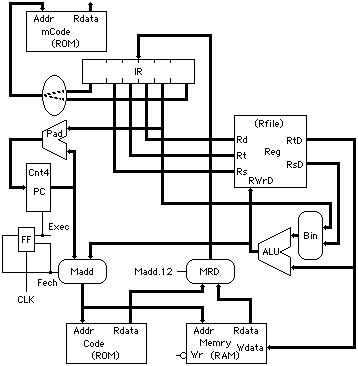
The front of the gate specification defines four memories: The first ROM and RAM are logically combined to be the main system memory; they are separate circuits mostly because the SPIM assembler puts code and data into different addresses. These are followed by two ROMs, which are are effectively programmable logic arrays (PLAs) and serve to decode the MIPS instructions (the floating-point ROM, FDROM, is not shown in this diagram). The dots in the binary ROM words are used as "don't-care" fillers (recognized as 0s by GateSim). Each location in a ROM is one decoded instruction, accessed by the bits of the top and bottom 6-bit segments of the Instruction Register (IR), and which should execute in one cycle. Each bit (or sometimes a cluster of bits) defines one control operation, such as enabling a conditional or unconditional jump, or else selecting the jump address, and so on. Almost all the floating-point operations have a single opcode (0x11), which is further decoded in the second PLA from IR bits not otherwise decoded. However, only the register transfer and conditional branches are implemented. Floating-point arithmetic is left as an exercise for the student.
Next in this specification is the Rfile macro defining 31 1-bit three-port registers, with the logic for reading and writing them. This macro is used for both the general register file and the floating-point registers, immediately following it. In order not to replicate the register selection decoder for writing the destination register, there are 31 separate decoded write control lines (register 0 cannot be written, and always reads out as 0).
Next is the Program Counter (PC) and the logic for incrementing it and selecting conditional jumps. The PC is only 12 bits, built up from three 4-bit counters. The low-order two bits are not implemented; they are always assumed to be 00. The PC is always incremented at the end of the Fetch cycle, and then conditionally reloaded at the end of the Execute cycle if a jump occurs. Conditional branches are relative addresses, so there is a separate adder to add the offset from the IR to the unincremented PC value saved from before it was incremented.
This specification has places to insert multiply and divide instructions, but they are left as an exercise for the student. The Hi and Lo result registers are already provided and functional for transferring to/from the general registers.
The ALU is only capable of three operations: Add, AND, and XOR (Add with the carry turned off). These are implemented in a 1-bit macro, which takes A- and B-inputs, the carry from the next lower bit, and a couple of control bits to select the operation. This version of the ALU is ripple-carry only, which takes two gate delays for every bit, and the clock has been slowed down to 100 gate-delays per cycle to accomodate it; a fast look-ahead carry generator can be added as an exercise.
Toward the end of the TinyMIPS specification file are the random logic control signals. Execution timing proceeds in two (rather long) cycles, Fetch, then Execute, generated by a flip-flop toggle (shon in the lower left corner of the diagram above). This bit controls whether the memory address comes from the PC or the offset+register calculation in the ALU for loads and stores. It also enables the execution of the register write-back and conditional branch logic in those instructions that do those things. An exercise could alter the timing to lengthen the slower instructions and speed up the faster ones, by replacing this flip-flop with a state counter. It would be completely eliminated for pipelining or other structural changes.
The end of the file is devoted to trace specification. There are a number
of trace specs that are commented out; these can be turned on to see some
of the machine operation in more detail.
1. Barrel Shifter. Implement a full 0-31-bit shifter in either direction, so that it executes in one cycle. Adjust the instruction decode so it knows about your instructions (sll, sllv, srl, srlv, sra, and srav).
2. Look-ahead Carry. Design and implement a look-ahead carry part that you can use to reduce the present 64-gate-delay carry propagation to something closer to 7 gate delays, so that add/subtract/compare operations take about the same time as logic operations. Adjust the control logic as necessary to achieve this timing.
3. Pipeline. Design and implement a pipeline execution unit, so that a new instruction starts every clock cycle.
4. State Machine Sequencer. Redesign the current instruction sequencer to use a finite-state machine (FSM) so that instructions that need to take longer do not slow down those that can go faster. Verify that all programs still work correctly.
5. Hardware Multiply. The current TinyMIPS circuit implementation has no multiply hardware. Your enhancement would implement a 32-bit signed multiply instruction (mult/multu) which starts when the instructioin is issued, then runs asynchronously until it finishes, leaving the product in the Hi and Lo registers.
6. Hardware Divide. The current TinyMIPS circuit implementation has no divide hardware. Your enhancement would implement a 32-bit signed divide instruction (div/divu) which starts when the instructioin is issued, then runs asynchronously until it finishes, leaving the quotient and remainder in the Hi and Lo registers.
7. Floating-Point Add. Your task is to implement a FP addition and subtractioin (add.s and sub.s) and the two converts (cvt.s.w and cvt.w.s, which use much of the same logic).
8. Floating-Point Multiply. Your task is to implement a FP multiply instruction (mul.s).
9. Data Cache. Build an associative memory cache which retains recently accessed RAM data with its addresses, and eliminates redundant reads from memory. Be sure to write data stores through the cache to main memory.
10. Instruction Cache. Build a cache memory that reads ahead the next few words of ROM memory, so that the next instruction is probably already in the cache when needed. Make sure you keep several words already executed, in case of small loops. For extra credit, decode unconditional jumps to continue fetching from the jumped address, essentially removing them from the instruction stream.
11. Byte- and Half-word loads and stores. The current TinyMIPS only loads and stores aligned full data words. Partial words and unaligned words require some extra logic. Implement it.
12. Parallel Processors. Implement a dual-CPU shared memory version of TinyMIPS. Note that you will need to resolve memory contention and provide for the two CPUs to start at different memory addresses.
Rev. 2003 November 19