void Weird() {
char * charArray[100];
int ix;
for (ix=0; ix<100; ix++) {
charArray[ix] = "Hello";
charArray[++ix] = "World";}
strcpy(charArray[49],charArray[50]);
if (*charArray[0]=ix)
cout << "Hello" << ", " << "World" << endl;
else cout << "Bye, violin" << endl;
} // end Weird
a. [5] How may times does the body of the for-loop
execute?
This is very poor form for a for-loop, because the control variable ix is incremented in the body of the loop as well as in the loop header, so the loop only executes half as many times as you'd expect from the loop header. Answer: 50.
b. [5] How many bytes are allocated for the variable charArray?
charArray is an array of pointers, and pointers are 4 bytes each, *100 = 400 bytes.
c. [10] What does the if condition test?
The if condition is an assignment, not a boolean comparison for equality; the final value of ix coming out of the for-loop is 100, which is a valid character (the letter 'd') stored into the first character pointed to by the first element of the character array, which happens to be the letter 'H' in the stored constant "Hello", which changed the constant to "dello".What is tested by the if is the value assigned, 100, !=0, which is true.
d. [10] What does this method print out?
The if condition is true, so you get the first cout statement rather than the else. Furthermore, the strcpy on the previous line copied one of the "Hello" strings (all even-numbered array elements pointed to the same "Hello" string constant in the code space) over on top of the "World" string constant pointed to by all odd-numbered array elements (they fortuitously being the same size), with the result that both string constants are (separately) equal to "Hello". Then, because the if condition is also an assignment, the first character of the even-numbered version of "Hello" got replaced by the letter 'd', rendering it "dello", so what is printed is the altered "Hello" followed by the altered "World", that is, "dello, Hello".
e. [10] On some computers this method crashes (segmentation fault).
Why?
If the code space is write-protected, then both the strcpy and the if condition assignment, which both alter string constants in the code space, will crash.
f. [10] Some C++ compilers give a warning for this program. What
hazard is it about?
Some compilers will catch the assignment where it doesn't belong, since this is such a common coding error.
2. [25] Assume you have defined in scope a fairly large class BigObject,
and you wish to pass parameters of type BigObject to a method doSomething.
What is the difference between the following ways to define this method
prototype? For each method signature, explain why or in what circumstances
you would prefer that signature, if so.
a. void doSomething(BigObject parm); This makes a copy of the whole object, which is a serious performance hit.
b. void doSomething(BigObject * parm); This passes a pointer to the object; the pointer and the data both can be changed.
c. void doSomething(BigObject & parm); This passes a reference (pointer) to the object; only the data can be changed.
d. void doSomething(const BigObject * parm); This is the same as (b), but the pointer cannot be changed, only the data.
e. void doSomething(const BigObject & parm); This
is the same as (c), but data cannot be changed. This is preferred.
3. [12] The following program compiles and seems to run, but it has a serious bug. What is it?
class Oops {
int * p;
public:
Oops(int x) {p = new int; *p = x;}
~Oops() {delete p;}
}; // end OopsOops MakeIt(int n) { /* make a new Oops object and return it */
Oops z = Oops(n);
return z;} // end MakeItint main() {
Oops v = MakeIt(7);
} // end mainThe constructor call in MakeIt allocates a new int and sets its value to the parameter (7). A copy of this object z is made for returning to the caller's v, then the destructor is called on the original z, deleting the pointer value. However that pointer lives on as a dangling pointer which is deleted again by the destructor call when v goes out of scope at the end of main().
4. [8] Give an analysis of the running time for the following algorithm:
sum = 0;
for (i=1; i<n;i++) // O(n)
for (j=1; j<i*i; j++) // O(n2)
if (j%i == 0) // O(1/n)
for (k=j; k>0; k>>=1) sum++; // O(log n)Net effect is the product of these individual order analyses, O(n2 log n)
5. [5] What is the purpose of a header node in a linked list?
To make it easier for list management methods to deal with insertions and deletions at the front of the list, by eliminating the special cases. No header node is needed just to keep a reference to the front of the list; it is sufficient to keep a copy of the list pointer for that.
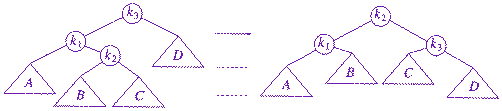
6. [20] Explain double rotation in an AVL tree, showing before
and after views.
Double rotation moves the right subtree of a left subtree (or correspondingly, the left subtree of a right subtree) up and around the top to balance an AVL tree, as in the diagram:
Letís say you have a B+tree block size of 8192 bytes and a (major) key size of 20 bytes and a data item size of 76 bytes. Letís further assume that there will be 720,000 data records in the final tree, but only 1200 unique major keys. Obviously there will be an average of 600 data items for each unique major key, so it has been decided to extend the key with a 10-byte minor key.
7. [10] What needs to be in each index block?
The index block should have links to M subtree disk blocks, and M-1 key values to distinguish them. With a key size of 20+10=30 bytes and a disk block number size of 2 bytes (shortint) there is space for M=256 such links in each index block with 30 bytes left over for such things as an uplink (needed for splits) and a block type. In memory the index items can be further elaborated by pointers to in-memory blocks (=NULL when not currently loaded). I accepted other numbers consistent with this reasoning.
8. [10] What needs to be in each data item in the leaf blocks?
Each data item needs one 30-byte key, plus 76 bytes of data, for a total of 106 bytes.
9. [5] How many data items can you pack into each leaf block?
8192/106, =77
10. [5] Approximately how many leaf blocks will the built file contain?
720,000/77, about 10,000 (assuming some partially filled blocks)
11. [5] How many subtrees can a single index block directly link
to?
M=256 (from #7 above)
12. [5] Approximately how many index blocks will be needed for the
built file?
10,000/256, =40 approximately (perhaps as many as 50 or 60, assuming some partly filled), +1 root
13. [5] What is the total file size of the built database (in bytes)?
How many blocks is that?
10,000+50 blocks, *8192, about 82MB
14. [5] How many bytes do you need to allocate in each index item
for linking to subtree blocks?
10,050 blocks can be enumerated in a 2-byte short int.
15. [5] On the average, how many disk accesses will be required
for a data item lookup?
One root, plus one index block, plus one data block, total 3.
16. [10] If you decide to pre-allocate the disk blocks in memory,
how many do you need to allocate in order to ensure that you have enough
to handle the worst-case access? Will that worst-case access occur when
building or searching? Justify the difference between your answer here
and to #16 above.
Worst-case when building the tree would occur when a leaf block splits and also forces an index block to split. No higher splits are necessary, so max five blocks in memory at once.
17. [5] Assuming a reasonably random key sequence during building,
how many leaf block splits can you anticipate during the build?
It turns out the sequence is pretty much irrelevant. You are going to get one less leaf block splits than there are leaf blocks, so about 10,000.
18. [5] How many index block splits are likely during build?
Like leaf blocks, you should get one less index block splits than there are index blocks, about 40 or 50.
19. [5] How many times can you reasonably expect two or more index
block splits to occur for a single insertion?
Never. To get two index block splits you have to have a tree depth of three or more.
20. [8] What is the largest number of index block splits you can
reasonably expect in a single insertion? How many times will this occur
in the course of building the entire file?
One. All 40 of them.
21. [5] How many times in the course of building the entire tree
will the program get a block from the disk, modify it, and put it back?
Once for each data item, as it is inserted into a leaf node, 720,000, plus one for each index block over a leaf block when it splits, 10,000, plus one for the root block whenever an index block splits, a total of 720,000+10,000+50, =730,050 (approximately)
22. [25] During the course of writing and testing your B+tree program,
you discovered that the C++ library string tokenizer has an undocumented
ìfeatureî (otherwise known as a bug) which makes it unusable for extracting
words from each line of source file text. Write a substitute tokenizer
in C++ that takes a pointer to the source line, maintains its own pointer
or index into that line which it updates for each word, and returns a pointer
to its own word buffer containing the next word extracted from the source
line. Ignore punctuation symbols as well as extra spaces, and make sure
words capitalized at the beginning of verses and sentences (and elsewhere)
are returned in a form that is indistinguishable from uncapitalized words.
You also need to recognize when there are no more words in the source line,
both to inform your caller that it needs to read another line, and also
to reset your internal offset. Are hyphens part of your words, or are they
counted as white space between words?
// in class ReadFile (or some such)...
char gotWord[30]; // to return with the next word token
int here = 0; // current index in source linechar * MyTok(char* inLine) {
int ix = 0; // size of returned word
char c; // current character being examined
while (true) {
c = inLine[here++];
if (c<'A' || c>'z' || c>'Z' && c<'a') { // hyphens are treated like whitespace
if (ix == 0 && c!= '\0') continue;
if (c == '\0') here = 0; // got terminal null
gotWord[ix] = '\0'; // not a letter, return what we got
return gotWord;}
if (c<'a') c = c+32; // decapitalize
gotWord[ix++] = c;
if (ix>30) { // too long, return what we got
gotWord[ix] = '\0';
return gotWord;}
} // end while
} // end MyTok