There seems to be some confusion on what threads and processes are, and why we should want them. The Feb.2004 issue of DDJ, p.76 has an article by a not overly skilled programmer discovering the value of threads in his real-time code, and inventing a not very sophisticated thread manager to make it happen. It's worth reading to understand why threads are a Good Thing.
Basically, when you have a lot of things that need to be happening all at the same time, and only one computer to do them, you must figure out some way to cycle between these jobs, giving each one some time to do a little bit of work before moving on to the next. In a batch system it doesn't really matter much if one job takes a long time before moving on to the next, but most computers today have real-time requirements, such as an internet connection possibly running a long download over a slow modem, while printing many pages of a document, while still being responsive to the user's mouse and keyboard. And if there is any CPU time left over, there might be some background processing the computer can do.
Before threads were invented, each part of the program was required to do some small defined quantum of work, then release the CPU to another part of the program. This is not hard to program, but it's easy to make mistakes, such as getting stuck in a very long loop and forgetting to put release code inside the loop. Users of the original MacOS are familiar with software done like this.
With system support for processes and threads -- a thread is really nothing more than a separate process with shared code and data, but a separate stack -- the operating system can be responsible for pre-empting a stodgy thread or process to give time to its peers, and the programmer can stop worrying about how long it has been executing. Furthermore, I/O-bound processes can be synchronized to their I/O devices automatically without worrying about what order the I/O service calls need to come in.
Consider a program that wants to read data from a slow device like the modem or a tape drive, and (perhaps after formatting it) print the data on another slow divice like a line printer. A simple-minded program might wait for some data from the input, then go print it, then come wait for some more data, then print that, and so on. Alas and alack! The modem data didn't stop coming when you were off printing the previous batch, so you have to poll the modem in the middle of formatting the data and transferring it to the printer. The complexity quickly gets overwhelming.
Instead, we design the modem reading program as a single thread, with a simple loop that accepts data and drops it into a circular buffer. If the buffer starts to get too full, you can send a message off to the source to slow down or wait or some such. Another thread pulls data out of the buffer, formats it, and sends it to the printer, completely oblivious to what the modem is doing. The system, meanwhile, gives a little time to the modem, and a little time to the format-print thread. Even better, the modem, recognizing that it is strictly I/O-bound, can run at a slightly higher priority, get some CPU time when a byte arrives, quickly store it in the buffer, then block waiting for the next byte. Similarly, the format program can block when the buffer is empty, but as soon as there is data there, start to format it and send it to the printer. When the printer gets busy on paper movement, this thread can also block, giving time to some third thread.
The important thing to remember here is that these are really separate
programs doing their own thing, and touching only their shared circular
buffer, and that only under controlled circumstances. The control is achieved
by semaphores, which are described in more detail
below.
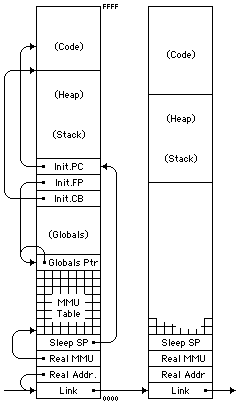
There is a lot of room for creativity and flexibility in laying out your memory space, but you should choose something that works for your system and document it, then stick to it (excpet to fix mistakes). In this example we put the essential process information at the beginning of the allocated memory block, at relative 0000. The first word is a link to other processes in whatever list this process is in, either the ready list or some semaphore; of course if it's running the link will be unused.
Assuming this to be a memory-mapped process, we need the real address of the Process Info Block (PIB). We also need the real address of its MMU Page Table, which is what gets stored in the MMU table register at physical memory location 1FFFE when this process is active. Finally, we need a place to save its saved stack pointer, for re-insertion in the CoCall target when awakening the process. Because the code is a fixed size determed at compile time, I put it at the other end of the local address space, then build the heap (variables allocated with new) down from there. The SandBox stack grows upward, so this is a natural. In CPUs where the stack grows downward, you might want to reverse the order. In any case it's convenient for the stack and heap to grow into the unused address space from opposite ends. Normally the OSL program allocates its own global variables on the (initially empty) stack, but some languages call for separate global space blocks, which you might allocate as shown.
When starting up a process like this, you need to load the code into its memory space, choose an appropriate global space, then set up the initial register values as show, with the initial CB pointing to the front of your code, the initial PC pointing to whatever byte that front word is an offset to, the initial frame pointer pointing to your globals pointer, and the initial stack pointer pointing to that frame pointer value. Note that the OSL compiler assumes that its startup code was called by a normal Call instruction, so it executes an enter#0 instruction, then proceeds to push its global variables directly onto the stack with an assumed offset of +6 for the first variable pushed. That means that the globals pointer, if it points to itself as shown, must have exactly one word (2 bytes) between itself and the initial CB on startup. That word would normally be the return address for when the program exits normally.
You should be aware that this arrangement of the PIB assumes that it is in MMU page 0, and therefore fully visible to the application program. If you place the globals pointer at the 1024-byte page boundary, then you can write-protect page 0 to prevent a malicious (or foolish) program from altering system-critical pointers like the link to the next process or its own MMU table.
If you are implementing disk-backed virtual memory, then all of this
gets written out to the program's region in the swap file, with only the
PIB and the initial top of stack in real memory. The program, when it starts
up will immediately hit a page fault, which is loaded in from the disk,
leaving all the rest of real memory free for other programs. When giving
the program new heap or stack space, you can mark it read-only in the MMU
table until the first write generates a page fault; after that you turn
on the write bit, and can therefore know the page needs to be written back
out to the disk before it is re-allocated to another program. Code space
of course never should be written into, so it remains read-only. In fact,
really clever memory managers never even allocate swap space for it, but
rather just map it directly from the object code file. That's pretty tricky,
probably too esoteric for a student exercise like this.
AppCode = new int[(size+1)/2]; // allocate a block big enough for codeThen at opportune times (I used the clock interrupt for this illustration), you can switch the context like this (again, an oversimplification):
AppPIB = new int[1024]; // probably big enough for stack and globals
if (AppCode==null || AppPIB==null) {
PrintStr("Could not allocate memory");
return;}
CodeBase = PEEK(&AppCode)+2;
fi = Open(".F");
nx = Read(fi,AppCode); // read it from the floppy
Close(fi);
PrintStr(" Got "); PrintNum(nx);
if (nx<ix) return;
PIB = PEEK(&AppPIB); // got it..
StakIx = 8; // allow 16 bytes for Process Info Block
Stack = PIB+StakIx*2; // the rest is user space
AppPIB[StakIx-1] = 0xBFFE; // branch to self (stall) for quit
AppPIB[StakIx+1] = Stack-2; // return address is that stall
AppPIB[StakIx] = Stack; // globals ptr, =FP
AppPIB[StakIx+2] = CodeBase;
AppPIB[StakIx+3] = Stack; // initial FP
AppPIB[StakIx+4] = AppCode[1]+CodeBase; // initial PC
AppPIB[3] = Stack+8; // initial SP, where Process Mgr can find it
AppPIB[0] = ReadyList; // link to front of ReadyList
ReadyList = PIB;
// Process management demo..The current version of MiniOS has moved this code into a separate subroutine SwapOut, which is also capable of handling semaphore blocking.
temp = CurProcess;
prior = ReadyList;
if (prior !=0) if (temp !=0)
if ((Mouse.H<320)!=(PEEK(prior+8)>0)) { // OK, swap it..
POKE(temp+6,SemSP); // save current process's SP in its PIB
ReadyList = temp; // move (formerly) CurProcess to ReadyList..
POKE(temp, PEEK(prior)); // .. linked to rest of ReadyList
CurProcess = prior; // swap top of ReadyList in
SemSP = PEEK(prior+6); // exit to it on next CoCall
prior = PEEK(prior+8)*320;
Clipper(0,prior,480,prior+320); // clip the display to its half
continue;}
The application programmer will write something like this to read a file (for example, data from the keyboard) and write it to another file (in this example to the screen):
// File I/O demoThe interesting parts of this compile into the following machine code (annotated):
import Files;
void main() {
char[] data = new char[20];
char[] copy;
FileId fi = Open(".K");
FileId fo = Open(".S");
int nx = Write(fo,"Type some data: ");
nx = Read(fi,data)/2; // byte count is returned
copy = new char[nx];
while (nx>0) {nx = nx-1; copy[nx] = data[nx];}
nx = Write(fo,copy);
Close(fi);
Close(fo);
} // end main
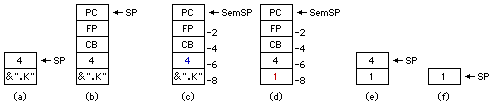
FileId fi = Open(".K");Consider first what happens in line 7 (the Open call). The compiler pushes two numbers, first the address of the file name (which in this case is in the code space, so it must calculate where that is), then a 4 representing the SysCall code for Open. The stack now looks like (a) in the following diagram:
8059 000007 line #7
805C 6000 call #0 ; gets address of next instruction
805E 010054 push 84 ; subtract from it offset to string constant array
8061 1D sub
8062 24 push 4 ; the SysCall op code for Open
8063 09 syscall
8064 05 pop ; discard op, leave result on stack as finx = Read(fi,data)/2; // byte count is returned
8081 00000A line #10
8084 4004 ldf 8 ; push contents of the variable fi
8086 4003 ldf 6 ; push address of dynamic array data
8088 26 push 6 ; the SysCall op code for Read
8089 09 syscall
808A 05 pop ; discard two of the three pushed values
808B 05 pop
808C 22 push 2 ; divide the result by 2
808D 1F div
808E 05 pop
808F 5006 stf 12 ; store it in local variable nxnx = Write(fo,copy);
80E2 00000D line #13
80E5 4005 ldf 10 ; push contents of the variable fo
80E7 4007 ldf 14 ; push address of dynamic array copy
80E9 27 push 7 ; the SysCall op code for Write
80EA 09 syscall
80EB 05 pop ; discard two of the three pushed values
80EC 05 pop
80ED 5006 stf 12 ; store result in local variable nx
The SysCall instruction pushes the processor state onto the stack, as in (b), then exchanges the stack pointer with the value stored in the interrupt handlers SemSP variable, then begins executing the interrupt handler code, in some distant part of memory, with its own stack and context. The handler code knows that its local variable SemSP now points to the interrupted code's stack, as in (c), so it can reach in and grab (at SemSP-6) the value of the pushed operation code (the blue 4) to decide what service is being requested. The 4 means this is an Open call, so it switches to case 4: to process the Open call.
The handler code for Open knows further that there is a file name parameter just under that 4 (at SemSP-8), which it can extract the pointer to and open that file, in this case the pseudo-file ".K", meaning Keyboard input. After opening the file (whatever that involves, which in the case of MiniOS is nothing, since the file is already open by default), the handler needs to return some kind of identifier to that now open file. This could be a pointer to the file control block, or as in MiniOS, an index into the open files table, in this case 1, which the handler knows to store back into the stack word that will be left after Open returns and finishes popping unused parameters, at offset SemSP-8 (shown in red), as in (d).
When the interrupt handler exits by its normal CoCall, its stack pointer is exchanged again with the saved SP in variable SemSP, making the user program once again current. The saved context is again popped into the CPU registers, leaving the stack after the SysCall operation as in (e). One final pop instruction leaves the result (f) ready to be stored into a FileId variable, or as in this example, already there. There is a detailed description of how a generic interrupt handler should be set up in the document Understanding Code.
The Read and Write calls perform substantially the same, except of course there is an extra parameter pushed onto the stack before, and discarded after, the Syscall returns.
If your OS is going to block the application program while waiting for I/O to complete, you need to do that here also. Switching to another task has already been described above, except that the blocked process is not added to the Ready list, but to a list of processes that are blocked, in the form of a semaphore, as in the following section.
Note that what is happening is that the SysCall interrupt
handler is essentially a separate program, which peeks under the covers
of the other (main) program to help it along from time to time. And because
interrupts are not re-entrant, you don't dare write code for use inside
the SysCall handler that makes recursive calls to SysCall,
such as memory manager or other file system calls. However, if you implement
the file manager and memory manager and the other OS services as their
own threads to which you send messages, then the SysCall
thread/interrupt handler can get in and get out, and these other threads
can go ahead and make their own SysCall requests, which
can be honored by the otherwise unoccupied handler.
A true semaphore is a special form of process list, which can either be a list of processes waiting on some event or resource, or else a count representing how many of these resources are available for processes before they must wait. There is hardware support for semaphores in SandBox, in that if there is a non-zero count (actually a negative number) then the wait instruction simply takes one count and continues without interruption. If the count is zero, or if there are already other processes waiting on the semaphore (positive PIBs, which must thus be in the first 32K of real memory), then the interrupt is taken, and the OS can do what is necessary to add this process to the list and swap in some other task from the ready list. This is described in much greater detail in the document Understanding SandBox Code.
In terms of what the code must do to support the wait interrupt, it's really the same as the Process Manager above, except that the process losing control of the CPU is added to the semaphore list instead of the Ready list. The address of the semaphore that triggered the interrupt is in I/O space, address 1FFFA (SignalWait.address). Signal is similar but in reverse, so that the top process is taken off the semaphore list and moved to the Ready List. The currently active process need not lose control of the CPU unless the unblocked process has a higher priority. The sample code in MiniOS handles both Signal and Wait, but it does not queue any processes to the end of their respective lists, which is probably a Bad Idea.
In the circular buffer application of the opening section, there would be two semaphores associated with the buffer. One of them, FillSem, would be initialized with a count equal to the size of the buffer, and the other, TakeSem with a count of zero. When the modem thread receives a byte, it checks (waits on) the FillSem to see if there is room in the buffer for it, then stores the byte in the buffer, then signals the TakeSem to let the other thread know there is data available. The other thread, meanwhile waits on the TakeSem until it is signalled that there is data available, takes the byte and signals the FillSem to let the modem know there is more space available, and then begins processing the data. If it needs to wait on the printer, that's OK, the incoming data will just pile up in the buffer. When the printer finishes, the thread is able to grab more data from the buffer, after waiting on the TakeSem semaphore each time to be sure the data is there, until it has caught up. In this application, there is no need for either thread or process to time out, they will share the load optimally, blocking to give the other thread processing time at just the time it is needed.
Starting a second thread up is a little tricky. Here is some sample code, which should run in User Mode. Starting up a new process should always be done in User Mode, except for linking it into the Ready List, which should be a protected system operation. This example cheats a little:
int[32] DemoFrame; // stack frame for new processvoid StartNewThread() {
// Ideally, this whole subroutine should be replaced with a NewThread SysCall,
// but then you cannot use FORK :-( this is a workable stop-gap)
int temp; // maps to DemoFrame[7] (allow 4 ints for PIB)
DemoFrame[10] = &DemoFrame[13]; // initial SP
DemoFrame[12] = &DemoFrame[4]; // initial FP
DemoFrame[4] = PEEK((&temp)-6); // copy my globals ptr
DemoFrame[5] = 0; // halt if it returns (it shouldn't)
temp = FORK(&DemoFrame[10]); // returns twice:
if (temp==0) return; // returned in caller's process
// otherwise returned in new process (first)..
POKE(temp-6,0); // clear caller's return value
// BETTER: Make a System call to do the next 4 lines...
POKE(CurProcess+6,temp); // save caller's SP in its PIB
POKE(CurProcess,ReadyList); // move caller to ready list..
ReadyList = CurProcess;
CurProcess = &DemoFrame; // make me current
while (true) { // OK, process the data..
Wait(mySemaphore);
...
Interrupts are both the cause and cure of our synchronization problems. Hardware-generated interrupts help to synchronize the software to external (usually input and output) events, and provide a means for sharing CPU time among multiple programs again so that they appear synchronized withinput and out (in this case the user interface). If it were not for the hardware (and user) timing constraints, there would be no need for interrupts or even multiple processes.
The first level of protection offered by the interrupt mechanism is that you cannot get another (hardware) interrupt while still servicing a previous one. Every CPU works this way; itís essential for system integrity. And because we can also turn interrupts off under program control, itís also possible to use the same mechanism to provide a monitor-like protection for any operation. However, it works by simply locking out all other processes, so the mechanism must be used carefully and sparingly. Keep your interrupt-level code short and simple.
The other mechanism is the semaphore. Semaphores synchronize user-level processes, but they are maintained by interrupt-protected code. Indeed, you must use interrupt-protected code for all operations involving a context switch, not just semaphores. Interrupts are those parts of the system code invoked through the iVector; there are exactly eight of them. Everything else should be synchronized and/or protected by semaphores at the user level (that is, with interrupts enabled).
An important part of your system design should be the partition of your
methods into those which necessarily must operate at interrupt level ("Protected"),
as distinct from those which would or should normally operate at user level.
Here are some ideas to get you started:
All interrupt-triggered I/O
Starting I/O transfer
Process context switch
Semaphore process linking
All application programsNote that many of the MiniOS functions do not obey this distinction (both ways). The reason for this is not to be hypocritical, but to offer especially simple code that is more easily understood. While the sample code mostly works, it is not safe.
Building a new process block
Allocating memory pages
File management
Any system operation that takes time
One of the problems you will need to solve in order to implement system services at user level, is how to get safely out of the SysCall interrupt service routine and into a user-level process, which can handle the service request before resuming the client process. Althought this has not yet been tested, I would recommend a separate process (you can start it like a separate thread from the main process using something like StartNewThread above), which maintains a list of processes desiring its services, and waits on its own semaphore to know when that list is empty. Whenever SysCall is invoked, its primary function then becomes very much like a combination of the Wait and Signal interrupts, except that the requesting process is always added to the end of the system services semaphore list, and then the services semaphore is signalled. Note that it is important to add new processes to the end of the list, so that the service routine can continue to operate on the process at the front of the list. When it finishes each task, it simply Signals that list as a semaphore, which puts the top process back into the Ready list, then waits on its own semaphore for another request.
If you do this, you probably want to consider making the memory allocator
a separate process (or leave it in the SysCall interrupt),
so that the other system services can use pointer variables and dynamic
memory without blocking itself. You might think of other services (such
as starting disk I/O) that need to be left in the interrupt service routine.
Revised: 2004 March 10