![]()
Today's lecture is in the field of computational linguistics.
The term "computational linguistics" means different things, depending on whether you come at it from the computational or linguistic side of things. When a computer scientist uses the term, we mean by it that we are using deep linguistic theory to inform our technology. A linguist uses the term to refer to using computer tools -- for example a word processor instead of a typewriter, or a database program instead of note cards -- while doing linguistics. More recently some linguists are getting a little more sophisticated: they now have computational tools doing morphemic analysis on digital representations of the sounds of speech, something we computer professionals have been doing in speech recognition for decades.
I gave myself away: my dissertation studies one aspect of computational linguistics from a computer science perspective. I do machine translation. I also use computers to do linguistics, but in a more profound manner than mere word processing.
Competent linguists consider machine translation to be a joke. Any naive person -- linguists consider all non-linguists, including computer professionals like myself doing computational linguistics, to be naive -- naive people tend to think of translation as a simple matter of word substitution. More precisely, Americans think of translation as a matter of word substitution.
Americans are, for the most part, unique among the world's people. We know only one language well enough to carry on a conversation in it. We are aware of other languages, and we pretend to study them in school, but we really don't know them. American technology dominates the world, and American dollars are the currency of the world. American armies won the two "world wars". We don't learn their languages, they learn ours. Most countries -- ours and a few Europeans and Middle-Easterns excepted -- have substantial populations whose mother tongue is something other than the official national language. Even if the USA were not a super-power, those people still grow up in an environment where knowing multiple languages is necessary to get along in their own society.
So when I give this lecture in an American context, I need to explain the nature of translation. If you are fluent in two or more languages, think of this as review. You already know this.
Translation is the process of taking a text or utterance -- we will confine ourselves to text, because teaching a computer how to wreck a nice beach [say that fast out loud] has its own problems -- we want to take a text written in one natural language, and say the same thing in another natural language. That is, we want the translated text to resemble what a person fluent in that language would have said if they had chosen to communicate that same message.
There is a joke that went around among the early computer scientists doing machine translation research in the 1960s. It seems they finally succeeded in programming a computer to translate natural language. The Soviet Union being the other super-power at the time, they decided to demonstrate the program's capabilities by translating an English sentence into Russian, and then back into English. They chose the familiar text, "The spirit is willing but the flesh is weak." It came back out "The vodka is good, but the meat is rotten."
What they were doing is word substitution. You can perform the same experiment yourself on any of the internet translation sites like BabbleFish, with comparable results. After 50 years of working on it -- computers have only been around since the 1940s, and this has been a computational goal from the beginning -- all this massive research in machine translation has not gotten us much closer to the goal.
Let me qualify that. Recent research in machine translation has focused on understanding natural language. Once you abandon word substitution, you come to see translation as two parts: first you understand the original text, then you say the same thing in the other language. The hard part is understanding. Humans spend years learning to understand their own language. We all did it as children, so we don't think about how hard it was. Children who learn a second language in the same time frame (by immersion, not merely a few hours in school) learn it well. Then the human mind snaps shut in our early teens, and learning that second language becomes much more difficult.
Let's look at the components of a machine translation problem.
We have an recognition phase, and a generation phase. But what do we mean by "recognition"? We are far from a credible cognitive model of the human mind, but (at least for translation) there needs to be some kind of black box here in the middle, where the "meaning" of the text is represented or temporarily stored between those two phases. It then turns out that both recognition and generation are translations in their own right, first from the natural language source text into that black-box meaning, then from the meaning into the target language.
![]()
Have we only made the problem harder? I think not. If we open up that black box, which we can and must do if it is to be done on a computer, we might abandon in the process our attempt to model human translation accurately and focus instead on making it work somehow.
Nevermind what goes on inside our brains, in our computer model this meaning box needs to accurately and unambiguously represent every possible concept and idea that can be said in any language.
Some concepts and ideas represent things, physical objects in the real world. They can be solid objects like the chair you are sitting in or the roof over your head, or fluid like the air you breathe. Objects are generally composed of or aggregated from smaller objects: the chair has legs, a seat, and a back. Even the air is made up of molecules of oxygen and nitrogen and smaller amounts of other gasses and maybe some particulate matter like dust and microbes and water droplets. We know about some of these compositions, but we don't think about them except as necessary to understand the text.
Take the sentence, "John went into his house and slammed the door." To understand the full meaning of this sentence, you need to know that houses have doors by which people enter, and that doors can be opened or shut.
This brings us to the next component of meaning, actions. Things can act and be acted upon. John moved from a position outside the house to another position inside the house. John was the actor or agent of this motion. The door changed state from being open to being closed. Although not explicitly stated except in the form of a conjunctive elision, John was the agent; he closed the door. The door was the patient, the thing John acted on when he closed it.
Which brings us to the next component, properties and qualifiers. The door is either open or shut. In fact it can be partially open, not wide enough to go through, but not closed so tight the wind couldn't blow it full open. We even have a word to describe that state: "ajar". Physical objects have color and transparency and size and weight. They have location and orientation, and relationships to other objects, like the door attached to the house by hinges.
Things can have state. State is a property that is expected to change over time. The door can be open or closed, or merely ajar. In our sentence the door went from open to closed; John went from outside the house to inside it. Part of an object's state is concerned with motion and orientation, another part is concerned with its relationship to other things. The house belongs (in some sense) to John. Usually that means he lives there. Many people own their own home, or at least some small portion of its equity. These ideas are implicit in the phrase "his house" and for complete understanding to occur, our recognition must accurately represent these ideas within that black box of meaning.
Actions can be qualified. The door can be closed forcefully (slammed) or gently. John can move swiftly or slowly, or any range between. Our sentence says nothing about how fast John went into the house, but he closed the door quickly.
There is also implicit information communicated by the choice of words. Slamming a door means somewhat more than that it was closed quickly. Slamming is associated with anger, which communicates a state of John's emotions.
All of this in one small sentence. All of this you perceived and understood immediately upon reading it. That is our recognition problem. More than that, we need some way to represent all this information, implicit and explicit alike, within the black box of meaning.
We start with what is called an ontology. An ontology is a set of atomic concepts representing every thing or action or state or qualifier that can be known, such as "John" and "house" and "slam" and "hinge" and "molecule". This gets muddy very quickly. Are "house" and "home" separate concepts in our ontology? What about "slam" and "close"? Or are they each a single concept, with qualifiers?
I started with a fairly simple sentence, and already we have several elements of implicit information. The door is attached to the house. John entered the house by the doorway to which the door is attached. John is angry. John lives in that house. John closed the door after he entered, not before. Some of these can be inferred from the choice of words, like "slam" and "his"; others can only be inferred from knowledge of how things normally operate. You do not normally enter a house by means other than a doorway (except Santa Claus on Christmas eve). You cannot go through a closed doorway (except the X-men). Doorways have doors (unless it is broken or in construction). People open and close doors (except in Star Trek). Even the exceptions I noted are significant by their abnormality. That is, we allow for exceptions, but they must be explicit. They are not stated in this text, so we assume the defaults.
There is more. Who is John? We are not told. In a larger context John would be introduced and connected to part of our meaning base. It's his house, but where is it? Why is he angry? What does entering the house accomplish in connection with that anger? If you are writing fiction, you need to answer those questions. If you are reading fiction, the social contract with the author permits you to expect answers. History is like fiction, except that the events really happened. Ah, we have another property of actions and things, that they reflect reality. Maybe John is a real person, and he really went into his house on the occasion in question, but he shut the door quietly. To say he slammed it thus constitutes a lie. So we have truth as an attribute of a proposition.
We can even talk about propositions and sentences as if they were things. We do that all the time. In fact, this whole lecture is an example of it. This gets us all tangled up in mathematical oddities like self-referential statements, such as "This sentence is false." The Greek philosopher put it more subtly: "All Cretans are liars. I am a Cretan." The implicit understanding is therefore that he is lying to us, so what he said is false, and therefore he is not lying. Can our ontology handle self-contradiction? People can and do: they simply ignore it. Computers in the movies smoke and spark and self-destruct -- which makes wonderful visual effects, but very unreal: it's quite difficult to make a computer able to do that, and nobody wants to. Real computers just get stuck in a loop or halt or (preferably) abort that program.
The best machine translation results come where there is a limited domain of discourse. Puns and poetry are disallowed. This greatly cuts down on the ambiguity. Thus if the translation software knows that the context is entomology, then "Time flies like an arrow" might be describing the preference of a particular variety of insect for a particular aerial weapon, or it might be a command to measure the speed of insects with a stopwatch the way you would do it for such a weapon, but it would not be a statement regarding the passage of time.
United Nations translators, who are professionals required to translate speeches in real time, have the advantage of assuming that most of their work is limited to the domain of politics and statecraft. It would be impossible for them if they did not know what was coming next. I have on various occasions listened to a live speech in one language I knew, each sentence followed by an off-the-cuff translation into another language I understood. Even where the translator is thoroughly familiar with the subject matter, sometimes he got stuck, having made some assumption about a person or object being discussed, and then discovering several minutes later that the pronoun or word he chose doesn't fit the what is now being said of that thing. One advantage of text translation is that you have the entire text to examine before you start to generate output. These ambiguities can be completely resolved in the ontology.
Let's assume that we have made some sort of executive decision and chosen what we hope is an adequate ontology. We already looked at some of the recognition phase of translation, determining what can be inferred from the choice of words and the context. As you can see, it's a very hard problem. Not even people get it right all the time. Some authors deliberately try to make it harder. We call their efforts poetry and jokes. Such texts often cannot be translated, because they depend on qualities of the presentation that cannot be reproduced in the other language. This is particularly true of puns. I knew one executive who bragged about breaking in his new secretaries by having them take a memo and type it up: "In the English language there are three ways to spell 'see'." Shorthand is phonetic, so the hapless victim would not detect the joke until she tried to transcribe her notes at the typewriter.
Now let's consider the other end of the translation task, generation.
If we have a good, language-neutral ontology, then generation of correct
text in that language is fairly straight-forward. Not trivial, for we must
choose appropriate words and sentence structures to represent the ideas
being translated, but far simpler than the recognition phase, because we
are starting with an unambiguous and well-defined meaning. Forget puns
and poetry, not even people can translate them. Either the attempted result
is not poetry, or if it's credible, a bilingual person will tell you it's
not the same. I consider it great sport reading the subtitles in a movie
where I know both languages, and watching for such inconsistencies.
This overview of machine translation sets the stage for a deeper consideration
of one particular translation project I am involved in. BTrans needs to
deal with all three blocks in our diagram, but the kind of translation
being considered offers some shortcuts to make the effort practical. BabbleFish
and the professional translators at the United Nations deal with a small
number of languages and a wide variety of texts (or speeches) to be translated.
Where the numbers are reversed (a small number of source texts in one language,
but many target languages to support) the problem becomes computationally
tractable.
We start with a limited domain of discourse, a fixed text corpus to be translated, which is less than a million words in English. Because it is limited and fixed, we can build an ontology to capture precisely the entire range of meaning in that text. BTrans uses a numbering system, slightly fewer than 8000 different concepts in its ontology. The numbers happen to be sequenced in groups by semantic domain, but that is irrelevant to the software. They are just numbers. We were fortunate enough that the ontology for this text corpus had already been largely defined by linguists. It covered things (nouns), actions (verbs), modifiers (adjectives and adverbs), and certain connectors (prepositions and conjunctions). To this we added concepts in the ontology to denote qualities normally reflected in English text by tense and person and number, as well as discourse relations not normally spelled out in the text, such cause, consequence, sequentiality, and so on.
English has only singular and plural; other languages syntactically distinguish dual, and a very few also trial (three), so we included those concepts in the ontology. English verb tense is handled with a variety of helper words and a very few inflected forms; other languages have vastly complex prefixes and suffixes and even stem modifications to inflect verbs (and often nouns) with a wide variety of attributes like when the action took place, who and how many people were involved, whether the action was instanteous or prolonged or repetitive, completed or unfinished, and so on. English has a surprisingly structured set of rules for inflecting the verb phrase to express some of these concepts, which I will get into shortly. The BTrans ontology expresses most of these attributes as individual modifier concepts, which the generation phase can decode and generate appropriate words or affixes in the receptor language.
Every language handles pronouns differently, so we removed all pronouns from the existing ontology, and put in their place a numbering system to link together references to the same thing or person. We depend on the generation phase to reconstruct pronouns according to the rules of that language.
Discourse semantics are mostly implicit in English. Many other languages have a much richer set of syntactical requirements to disclose the relationship between sentences and clauses; some others have even less than English. We try to encode as much information as can be inferred about the clausal relationships, so to serve both ends of the spectrum.
Several Pacific rim languages have a curious feature in their verb inflection obscurely called "switch reference." Each dependent verb in a sentence is inflected (among other things) by the person and number of the subject in the following clause, a sort of antecedent clue as to what's coming. In order for BTrans to generate correct Awa sentence structure, the generator needed to examine the next clause and determine its subject. This was further complicated by the fact that clause dependency in Awa differs somewhat from the way relationships are encoded in the semantic representation, so there was some restructuring going on at the same time, resulting a rather complex analysis pass before text could be generated.
This brings me to the structure of the semantic representation within our "meaning" box. A simple linear string of tokens is unworkable, because the order is so arbitrary between different languages. Some languages are "head initial" where the key word in each phrase comes first, followed by the modifiers. American Sign Language and spoken French do that with noun phrases; some other languages also put the verb before the subject. "Head final" languages put the key word last in its phrase; even prepositional phrases have the preposition -- actually, in their case, it's a post-position -- after the noun it controls. The Pacific island language Awa did that, with the main verb at the end of its clause after the subject, and the main clause at the end of the sequence of dependent clauses. Those are the two extremes; most languages have various exceptions. English is a mixture slightly closer to head initial than head final: our verb comes in the middle of the clause (except under inversion; more about that shortly) after the subject, but before the object. We have prepositions (not postpositions), but nouns follow their modifiers. German (like English) inflects its first helper verb, then pushes all the main verbs to the end of the clause, so you need to wait to the end to find out what action took place.
The BTrans semantic representation abstracts the semantic structure away from surface representation by encoding the relationships as a tree structure. The main proposition or clause is at the root of the sentence tree, with subordinate clauses branching off from it. All actions are fully propositionalized, that is, there are no abstract nouns in the semantic representation, because some languages have no such thing. To encode "Love is a many-splendored thing" where "love" is an abstraction, requires that we build a proposition "somebody loves somebody," then build an orienter proposition over it, so it comes out literally more like "[the situation] is good when (somebody loves somebody [else])". "Splendor" is a poetic word, not used in common English-language discourse; it generally refers to visual beauty, but is only metaphoric in this sentence. As I pointed out previously, poetry does not translate well. We can tag metaphors and add them as explanatory information in the semantic encoding, so that languages which support those particular images can use them, but it's a lot of extra work, both in the encoding, and in the generation.
You may have noticed that I'm using the word "encode" rather than "recognize" to refer to the front end of the BTrans translation. There is a reason for that. Recall that the recognition phase is by far the hardest part. We want a usable tool, not merely a research vehicle. Recall also the context in which this tool is to be used, where there is a relatively small fixed corpus to be translated. We can afford to push the entire recognition phase out of the software into the lap of humans, who are very good at understanding what they read, and can be trained to encode it in the rigid but unambiguous semantic tree representation used by BTrans. Then we can focus on the rather easier job of generating text in a variety of languages.
Before getting into detail on how the BTrans generator works, I'm going to say something about my dissertation, because BTrans uses fundamentally the same process we use for building translation tools widely used in the industry today. The software tool is called a "compiler" and it translates from a very artificial language like Java or C into an even more artificial language, which is the ones and zeroes of machine language. The technology is built on the deep linguistic theories developed by linguist Noam Chomsky, and the mathematics behind it works well in understanding not only how our artificial languages must be structured, but also what can even be computed. That part is subject matter for graduate courses in computational linguistics and computability theory, which we need not get into here.
Compilers work the same way as I have described for BTrans, with a "front end" recognition phase, which translates the source language into some language- and machine-independent intermediate representation, followed by a "back end" or code generation phase, which translates that intermediate code into the ones and zeroes of machine code. My dissertation addressed the kinds of things we can do to intermediate code represented as a tree, while preserving correct semantics -- yes, we use the linguistic terminology -- across the translation.
There is voluminous research literature concerned with processing linear code in non-linear ways; a tree-structured intermediate code eliminates most of the hassle, because the data is there within reach where you need it when you need it.
Consider a simple C or Java command,
x = y + 4*z;You cannot just process this command in linear, left-to-right order, because the computer does not and cannot know what to put into variable x until it has evaluated the expression to the right of the equal symbol. It could load y into a register, but if you have a limited number of registers like the Intel Pentium, that would be a bad idea. It's much better to compute the value of 4*z by fetching z, shifting it left two places, then add y to it, and finally store the result into x, in that order.
So the compiler can do this by building a stack representation of the intermediate values, or it can build an intermediate code tree something like this:
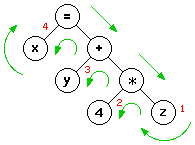
The tree representation has the advantage that you can transform it in interesting ways to effect a variety of interesting speedups, and then simply walk the tree in a suitable order (green arrows) to pick off the tokens from the nodes (red numerals) and directly translate them into code. If this were a computer science course, the process would make an interesting exercise for the student, where you get to actually write the compiler to do that. It's not that hard, once you know how it works. But they didn't tell me what discipline I should assume of my students. You are off the hook.
Similarly, when we do a tree representation of the intermediate semantic meaning of the text to be translated, the generator phase of the program just chooses some order to walk the semantic tree, and plucks off the concepts from the nodes as it goes by, generating text in the correct order on the fly -- not unlike how we speak and write. Think about it for a minute: You are looking at the door that John is going toward, and the house it is attached to, and the door slams. That is uppermost in your mind, but you don't just say "The door slammed and John went into the house, and John lives there." That may be the order you thought of it, but you speak it in natural English order, without a second thought. In the Pacific island language Awa, it might come out (literally)
door John slammed+near-past+next-3-masc-sing after his-house+place he-went+near-pastand they would say it that way without even thinking. And you could get both the English and the Awa translation from the same tree structure, just by varying the order you walk the tree and when you plucked off the concepts for text generation, here numbered in red for English, blue for Awa:
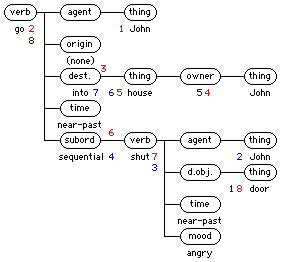
The key to making translators that do this lies in what we call grammars.
A grammar defines or describes the rules for making syntactically correct
sentences. For example, a tiny fragment of English grammar describes the
fundamental word order of a clause, two (of several) forms for the two
different kinds of action in this sentence:
| clause | = subject | mo-verb | origin | destination | modifiers | |
| = subject | tr-verb | object | modifiers |
In our sentence we have two clauses, "John went ... (into his house) (and ...)" and "[John] (closed) the door [angry]". The second clause is one of the modifiers on the first, connected by a subordinating sequential conjunction "and". Your 6th-grade English teacher told you that "and" is a coordinating conjunction (and she was technically correct), but the clause is implicitly subordinated in this sentence. We encode the deep meaning, which may not match the surface structure. The phrase "into his house" is a destination of his motion; personal motion is not transitive and takes no direct object. However motion normally has both a origin and destination, so we encode also an implied origin. English and Awa both permit that origin to be silent, but other languages are not so forgiving. When generating English, we simply omit the unneeded implicit origin.
Similarly we have rules for noun phrases, for example English proper names take no article; Greek names do. English possessives replace the article. And so on. These are arbitrary rules peculiar to each language.
Let's look at a particularly complicated grammar rule in English, the English verb phrase. There are five fixed slot positions, which may or may not be filled, and syntactic rules for the content of each position and its effect on the next populated slot. Any or all of the slots can be vacant (blank) except the last, which contains the primary verb. Consider the simple transitive verb "see". Here are the slots fully populated for future perfective continuative passive:
He will have been being seen.This simple sentence consists of a subject and a verb, nothing more. But oh, what a verb! We consider the slots in reverse order.
The first non-vacant slot is always inflected with time (present or past) and number (singular or plural, if applicable), if it can be. The final slot always takes the main verb. If the final slot is the only one filled, then it's inflected:
He sees, they saw, I see. [Slot 5 only]The fourth slot, if filled, is always a properly inflected form of the verb "be", and it requires the main verb following it to be in the past participle form, making it passive. Intransitive verbs never fill this slot.
He is seen, they were seen. [Slots 4+5]The third slot is likewise a properly inflected form of the verb "be", and it requires the following non-vacant slot -- that is, either the fourth slot if not vacant, or else the fifth slot otherwise -- to be inflected as the present participle, making the action continuative.
He is seeing, they were being seen. [Slots 3+5, 3+4+5]The second slot is a properly inflected form of the verb to have, and it requires the first non-vacant slot following it to be past participle again, making the verb perfective.
He has seen, they had been seen, I have been seeing. [2+5, 2+4+5, 2+3+5]The first slot is used mostly for uninflected helper words, such as the future helper "will" and the mood and ability controllers "might", "could", and so on. The fully inflected helper verb "do" is also sometimes used in the first slot for emphasis. The first slot requires the next following non-blank slot to be in the infinitive form, and thus forms the future or subjunctive or whatever that helper word controls.
He does see, they will be seen, I should be seeing, we may have seen. [1+5, 1+4+5, 1+3+5, 1+2+5]Did you notice that? Each slot affects the inflection of the next non-blank slot, whichever it is.
Questions trade the positions of the subject and the first non-blank slot, but never the main verb. If none of the other slots would be filled, the properly inflected verb "do" is inserted into the first slot before the inversion.
Will they see? Have I seen? Are we seeing? Were you seen? Does he see? [1+5, 2+5, 3+5, 4+5, (1)+5]Negation works the same way, with the negative word "not" inserted after the first non-blank slot, but never after the main verb, so it again requires the verb "do" if no other slots are filled. Most of the helper words contract with the negative, forming a single word.
They will not see, we aren't seeing, you weren't seen, he doesn't see. [1+5, 2+5, 3+5, 4+5, (1)+5]When negation is combined with a question, contraction causes the negative to cling to its verb during inversion, and not otherwise.
Doesn't he see? Will they not see? OR Won't they see?Any attempt to violate these rules is ungrammatical and sounds odd or foreign:
*I might could do that. *He is having seen. *They saw not.
This is your language! Every one of you, if you were raised in this
country, knows how to do this very complex word placement and inflection
correctly, without thinking about it. Other languages have other, equally
bizarre, grammatical rules. At least they can be codified.