NWAPW Year 2
Technical Topics
(Working Draft)
(Back to Part 1)
Part 2: Computational Image Analysis
Some or all of the analytical methods used in the human eye can also be
used in computational image recognition, but where the human eye does massive
parallel processing, our computers tend to be linear and sequential, albeit
somewhat faster (nanoseconds instead of milliseconds for atomic operations).
The human eye concentrates its color detection and high resolution into
the fovea (center of the eye), leaving the rest of the eye to see only
light and dark and motion. We compensate for this narrow focus by darting
our eyes around to focus on one thing after another in rapid succession.
Computer images are the same resolution and color depth all the way
across, and it requires a lot more processing to integrate constantly shifting
views so that their objects can be seen as the same after the scene has
shifted. Even Fourier transforms are expensive.
Consequently, we are forced to make trade-offs in image resolution and
recognizing pattern variation in object detection. A pedestrian wearing
a patterned shirt will be much harder for the computer to see against a
complex background than for the human.
RGB vs YUV
We need to understand different color models to get the best performance
in object recognition. Human eyes see three dimensions of color, basically
long-wave (red), short-wave (blue) and mid-range (green). So our video
technology supports this with three color channels, and our printing technology
supports the same dimensionality with three ink colors.
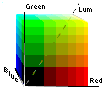
This is a color cube, with the three dimensions (red, green, and blue,
RGB)
explicitly shown. If you imagine the zero at the far end of the diagonal,
then the three dimensions are CMY (cyan, magenta,
and yellow). It's the same cube, only we have negated all the coordinates,
so CMYK (for blacK, because most colored inks are
not pure enough to get a good black, so they add black ink for that) is
essentially merely a coordinate change from RGB.
DigitalTutors
has a video explaining the difference between RGB
and CMY.
Except for sharp transitions in brightness, like the edge of a shadow
(and sometimes even then), human vision tends to down-play differences
in brightness not accompanied by differences in color or pattern. In normal
RGB
(red-green-blue) color images this is computationally difficult, because
brightness dominates the differences. One way to deal with this issue is
to convert the color space to luminance+hue+saturation (called YUV,
or sometimes also HSB or LUV),
then disregard most of the luminance.
Marco
Olivotto spends a lot of time in a video promoting PhotoShop explaining
how their "Lab" color model (essentially YUV) lets
you do interesting things with colors by deleting the luminance. Here are
some other links you might find useful:
Jamie McCallister's video "RGB
vs YUV Colour Space" explains YUV in video encoding.
Joe Maller:
RGB and YUV Color (includes links)
Reddit neural nets discussion "Is
there an advantage to encode images in YUV instead of RGB?"
BasslerAG FAQ "How
does the YUV color coding work?"
StackExchange "Why
do we use HSV colour space in vision ... processing?" is very relevant
Colored Object
Detection, 6-second clip with luminance deleted
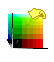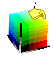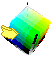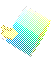 If
you imagine the Cartesian coordinate system of RGB
as an XYZ 3-space, a cube in one quadrant, black (0,0,0)
at the front bottom-left corner and white at the diagonally opposite corner,
and then you pick up this cube and rotate it so that black-white diagonal
is a vertical axis around which the other dimensions can spin, that's the
transformation.
If
you imagine the Cartesian coordinate system of RGB
as an XYZ 3-space, a cube in one quadrant, black (0,0,0)
at the front bottom-left corner and white at the diagonally opposite corner,
and then you pick up this cube and rotate it so that black-white diagonal
is a vertical axis around which the other dimensions can spin, that's the
transformation.
Why is this important? It turns out that the representation we choose
for our data can radically affect how we think about it. Newton (in England)
and Leibniz (in Germany) both
invented calculus about the same time, but Leibniz's notation is far
more intuitive and easy to do other mathematical operations on, so we now
use his work and ignore Newton's entirely -- except maybe to observe that
Newton was probably first. There are various notational transformations
that we can apply to our data to make it more tractable for different kinds
of processing. One involves seeing the data in the frequency domain instead
of time or space, which makes Fourier transforms (see the next
paragraph) useful. Another notational transformation is spatial coordinate
systems. We are familiar with "Cartesian coordinates" (named
for Descartes, who invented it), which is useful for placing things
in an absolute reference system based on perpendiculars. Pinning one or
more of those coordinates to a particular point (often the observer) produces
a numerical system more appropriate for things like ballistics, where you
want to know where to point your cannon and how much powder to load in
it in order to hit a particular target.
Color space is one of those systems where coordinates matter. Real light
-- the photons we experience as visible light -- might be closer to YUV
than RGB, where the wavelength of a particular photon
= hue, how many photons there are at that wavelength = luminance, and how
many photons there are at other wavelengths = saturation. The human eye
has "cone" receptors for three bands of color, so (for us) three independent
numbers can define any visible color (which makes it a 3-dimensional space,
like the cube above), but different coordinate systems give us radically
different abilities in terms of processing power. Even though human eyes
detect light in the RGB color model, it is internally
converted to luminance + hue + saturation for thinking about it (including
object recognition). None of us ever thinks about a certain shade of orange
as "um, yes, it has some green but more red than green" (unless we are
specifically trained in RGB technology) because we
do not see "green" in the color orange at all, we can only imagine that
it's there.
Luminance
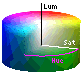 For
our purposes, luminance (and to some degree also saturation) needs to be
deleted from the analysis, which is much easier in a YUV
color space. It's fairly easy computationally: luminance is the sum (average)
of red+green+blue samples, and saturation is the maximum difference; hue
and saturation together is a polar coordinate vector (seeing red, green,
and blue as three 120-degree thirds of a circle) where saturation is the
distance from the center (white vector length) while hue is the (pink)
angle of the vector. Luminance is the third dimension, black at one pole
and white at the other (the black center line in the image to the right).
The coordinate transformation consists of only adds and subtracts, which
are much faster and use less hardware than multiplies and divides.
For
our purposes, luminance (and to some degree also saturation) needs to be
deleted from the analysis, which is much easier in a YUV
color space. It's fairly easy computationally: luminance is the sum (average)
of red+green+blue samples, and saturation is the maximum difference; hue
and saturation together is a polar coordinate vector (seeing red, green,
and blue as three 120-degree thirds of a circle) where saturation is the
distance from the center (white vector length) while hue is the (pink)
angle of the vector. Luminance is the third dimension, black at one pole
and white at the other (the black center line in the image to the right).
The coordinate transformation consists of only adds and subtracts, which
are much faster and use less hardware than multiplies and divides.
Fourier Transform
Both RGB and (especially) YUV
representations of an image give an absolute value of the luminance at
each pixel. When that varies across the image, you get patterns (stripes
if the variance is in one dimension only, dots or checks or more complex
patterns in two dimensions). Most people familiar with sound recording
and high-end playback equipment know about band-pass filters for adjusting
the highs and lows separately, which is seen as a graph, volume against
frequency. In the human ear this is how hearing works, the different frequencies
sensed in different parts of the ear, rather than the absolute air pressure
measured as it is in a microphone or delivered in a sound system's speaker,
see TheFourierTransform.com.
The relationship between pressure over time compared to amplitude over
frequency was investigated by the French mathematician Jean-Baptiste Joseph
Fourier, and the conversion is something like a coordinate transformation,
now called the "Fourier transform," except it's more complicated than converting
Cartesian coordinates to polar. There are algorithms called "fast Fourier
transform" (FFT) but they still involve trigonometric
function calls on all the data, for example:
Overtones,
harmonics, and additive synthesis
A
gentle introduction to the FFT
The Scientist and Engineer's
Guide to Digital Signal Processing
An
Intuitive Explanation of Fourier Theory
Trig functions on 8-bit image data can be as fast as a table look-up,
so the computational cost is not as bad as it might at first appear. However,
the frequency analysis of the image data is not as useful for recognition
as the other features. Brayer
offers some recognition benefits, but mostly concentrates on other stuff.
Edge Detection
Edge detection looks for sudden (but not transitory) shifts in brightness
or hue (or saturation) across the scene. Normally you do not want to be
fooled by momentary blips -- perhaps due to dust on the image plane or
insects flying around or even quantum fluctuations in the sensor electronics
-- so you need to "despeckle" the image before looking for edges. I use
a technique known as the Gaussian average (blur), which computes a running
sum of the current sample plus the previous sum, divided by two (right-shift
is very much faster than an actual divide). The result is that long-term
changes are preserved, but one-pixel blips are reduced. Digital signal
processors (DSPs) are designed to pipeline mathematical
operations so that even multiplications effectively take only one clock
cycle each; consequently the commercial image processing algorithms use
a lot of multipications, like for example in Gaussian
Smoothing.
Early small computers didn't even have a hardware multiply, everything
had to be done with adds and shifts, so programmers tended to favor algorithms
that minimize multiplications. I don't know of any fast divide hardware
(even today), the Intel chips tend to do it with Newton
approximations (a table look-up followed by a few steps of multiplication
and subtraction); with clever algorithm design, most of your divisions
can be converted into one table look-up and a single multiply. But none
of that is needed for simple Gaussian smoothing.
Identifying Pedestrians
Identifying pedestrians (in the path of an autonomous vehicle) is probably
the most difficult task facing the designer -- except maybe cyclists, but
in most parts of the country the climate discourages cyclists most of the
year, which tends to discourage them the rest of the year also. Walking
is something humans do naturally, no extra hardware or learning required.
That's why you will see far more pedestrians than cyclists in places cars
might be driving -- except in small flat European countries like
Holland.
This video has a segment at 29 seconds where they are picking out people,
but they don't say how they are doing it:
OpenCV
GSOC 2015
For purposes of this project, we can make some simplifying assumptions,
like requiring the pedestrians we detect to be wearing solid, bright colors
(no detailed patterns, no bland colors that blend in with the background).
Thus it becomes a simple matter of finding blocks of solid color, and then
ignoring those blocks that are not credible pedestrians. That part is hard
enough, we don't need to add more difficulty on the first cut.
This project has the additional advantage that it's mostly computational.
Other than acquiring the video stream, it can all be done in an average
personal computer in a conventional programming language like Java.
Any questions
or comments? This is your project.
Tom Pittman
Next time: What's Next?
Rev. 2017 April 29 (18Jan24)